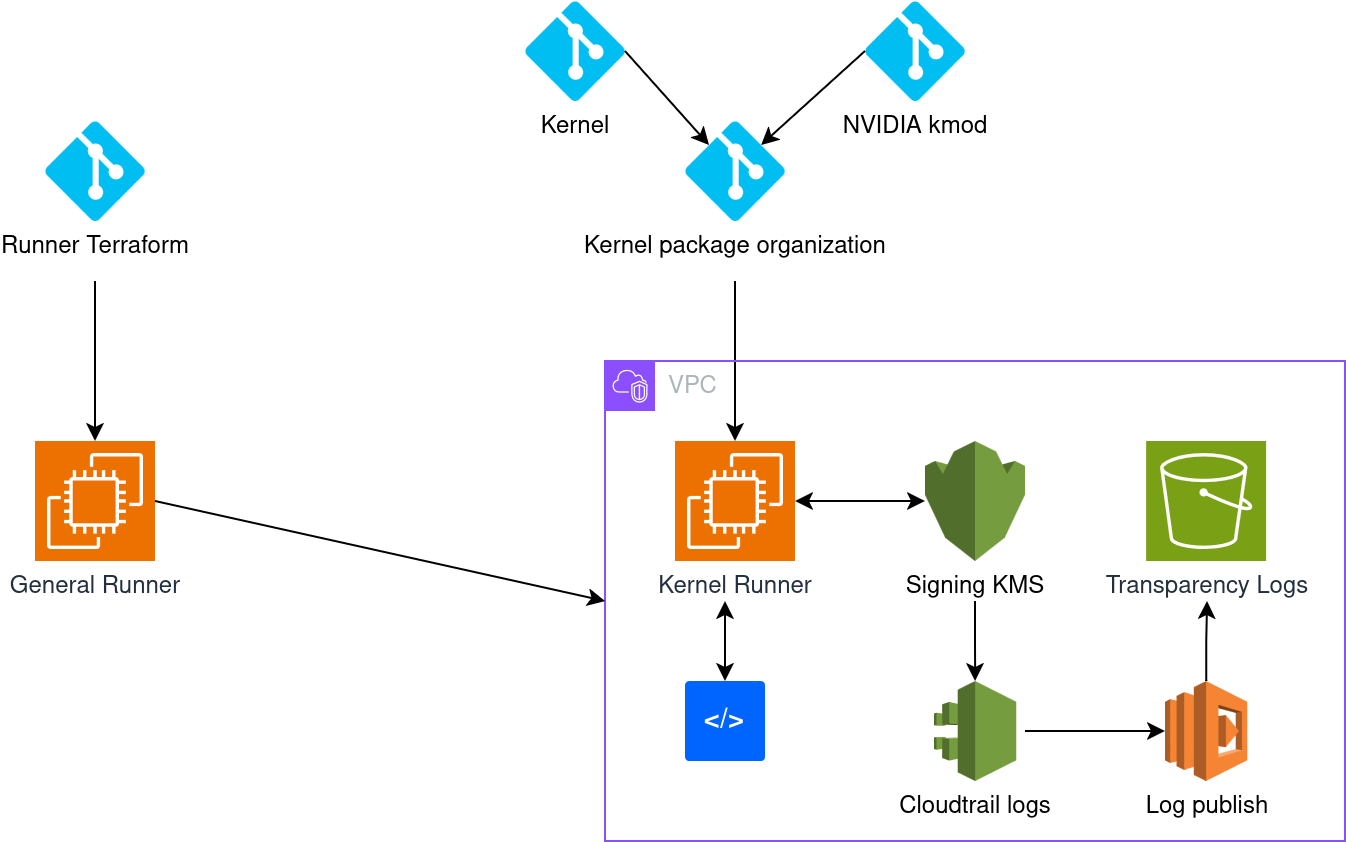
Hear me out…
TL;DR
Synchronizing component lifecycles reduces complexity in a collection, which benefits collections that are productized. Counter-intuitively, it is harmful for collections that are not products. Modularity was one of a series of mechanisms to support asynchronous work in Fedora, illustrating that asynchronous work is something that developers need. One way that Fedora could attract developers may be to provide a federated, language-agnostic source code registry to help them build and distribute software.Reading the history of a now-defunct Fedora feature called “Modularity,” one passage in particular caught my attention. The document described “a classic problem that Linux distributions have faced: the “Too Fast/Too Slow” problem.”
I think the problem is not that some components move too fast or some move too slow, it’s that independent developers work asynchronously, and distributions try to synchronize them. That might sound like a trivial distinction, but I think understanding the difference is key to making the distribution more scalable and expanding the developer community.
Let’s consider the example of a synchronous system.
Red Hat Enterprise Linux is a system that (within several categories) synchronizes the lifecycle of its components. That’s one of the things that Red Hat is selling. Rather than seeking support from thousands of projects individually, customers have one vendor to work with. Rather than thousands of individual release cadences and maintenance windows, customers have one cadence and maintenance window to which thousands of components have been synchronized.
Synchronizing those lifecycles is expensive. Red Hat engineers take on the responsibility of fixing bugs and security issues for the components they support for years past the end of upstream maintenance. Even with thousands of professional developers, Red Hat Enterprise Linux supports a far smaller set of components than Fedora does.
This process is one of the things that makes Red Hat Enterprise Linux a product. The lifecycle and feature set are tuned to a specific purpose, making them useful for a specific market segment.
In many ways, Fedora exists in contrast to that model. Rather than a small, focused set of features, Fedora tries to distribute as much software as possible. Rather than a large professional staff of engineers, much of Fedora is maintained by volunteers. Rather than unifying lifecycles, Fedora uses a rapid release cadence, a fairly short maintenance window, and in some cases rolling release packages to minimize the amount of downstream synchronization necessary to ship a collection of components while their lifecycles naturally overlap.
The purpose of productizing a release is to allow an organization to act as a vendor in place of upstream projects. It makes the organization a middleman, placing them in between users and the upstream projects, so that their customers have one support contract to maintain. Fedora is not that. Fedora should do the opposite of that. As a community project, Fedora should minimize the separation between users and upstream projects. Fedora should bring those people together.
Still, many Fedora policies imitate the superficial aspects of RHEL. A new package must be “the latest version” (as if there is only one). For most languages, components must not bundle their dependencies. Each component will provide only one version unless extraordinary steps are taken. Branches in the dist-git repositories represent Fedora releases, not the upstream project’s release series. These policies create something that’s product shaped, but lacking the staffing that allows RHEL to function as a product.
Those policies contrast with the world of package registries and direct publishing channels used by developers outside the realm of software distributions. Outside of distributions, developers are free to publish multiple simultaneous release streams under one component name (the same way that Fedora ships multiple simultaneous releases of the distribution). Developers can readily use a version from any supported release series of their dependencies. Developers are free to bundle dependencies, for better or worse… Some developers use this to avoid tracking updates, but others bundle to allow tighter integration and faster delivery of features developed in the dependent project. Strictly prohibiting bundling in Fedora ignores the value of collaboration in upstream projects, and actually creates silos which do not naturally exist in the Free Software model and which make small projects less sustainable.
Many of the things that are difficult in Fedora are difficult because we try to synchronize a massive collection of packages, like RHEL, rather than enabling developers to work asynchronously, like a package registry. Synchronization is difficult even for professional developers, but it’s reasonable when creating a product and taking on the maintainer role. Synchronizing the collection isn’t just difficult for volunteer packagers, it’s harmful when responsibility for fixing bugs remains with the upstream projects. Even with a rapid release cycle and a short maintenance window, Fedora maintainers do have to synchronize some packages. In some cases they approach that problem by modifying a project’s dependency information to allow it to build against a dependency version that the developers haven’t tested. That not only annoys developers by periodically creating bug reports for what is effectively a fork, the presence of that patch in Fedora makes it more difficult to automate future patch-level updates. When maintainers don’t modify a package to synchronize it with the dependencies in the release, they may need to create a duplicate version of a package for the version they need. At best that process involves tickets, and typically it involves asking the owner of the dependency to do the work. All of this is redundant work, unnecessary when developers are empowered to publish their own releases.
One of the problems that modularity solved was allowing packages and sets of packages to evolve asynchronously with the rest of the distribution. That’s necessary for lots of non-trivial software, where there are deep integrations between software components. That deep integration often indicates collaboration between projects, and we should encourage that. Fedora’s policies against bundling packages sometimes makes project collaboration more difficult.
For example vllm needs a very recent PyTorch, but a slightly older Python3. That’s not impossible in Fedora. A maintainer could request a fork of PyTorch. But there is a lot of friction. In particular, if the maintainer of the application wants a branch of a dependency owned by someone else, and if that maintainer doesn’t want to manage another package, it may be difficult to move forward.
Illustrations might help explain why Fedora’s synchronization makes their work less useful to developers, and how a minor change could make them significantly more useful.
In upstream projects with stable releases, it’s common to use branches to represent each release series.
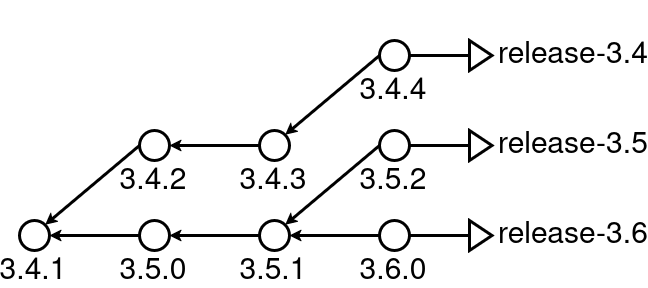
In some cases, especially for projects that have a cadence similar to Fedora’s, Fedora’s release branches follow very similar paths.
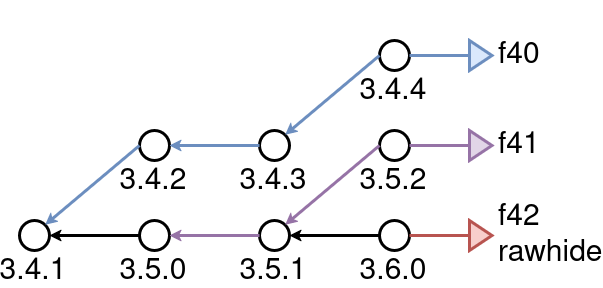
In other cases, Fedora’s release branches might rebase from one upstream release series to another. Or, Fedora might not have a branch representing an upstream release series at all, because no Fedora release is ready to use it. In either case, Fedora’s repositories don’t lend themselves to reuse as a general purpose source code registry because developers can’t reliably select a release series to follow, without synchronizing to a Fedora release.
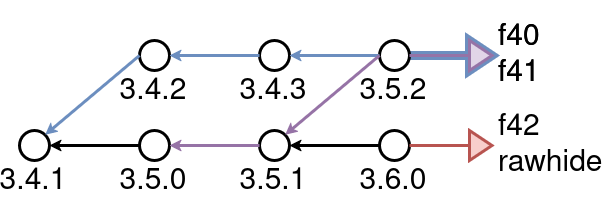
If Fedora’s dist-git repos provided branches that represented upstream release series, developers could define a complex build, without being limited to one centralized package registry (like PyPI), and without writing long shell scripts to do it.
This hypothetical example might use Fedora 44 packages where no specific branch is called for, but build specific releases of Python3, PyTorch, and vllm, and the resulting RPMs could then be used to create a container image in which some of those RPMs are installed.
base: fedora-44-x86_64
build:
- type: dist-git
url: https://src.fedoraproject.org/rpms/
packages:
- python3.11:release-3.11
- python-torch:release-2.11
- type: git
url: https://github.com/vllm-project/
packages:
- vllm:releases/v0.20.0
install:
type: container
base_image: registry.fedoraproject.org/fedora:44
tag: vllm:latest
registry: quay.io/vllm
packages:
- vllm
Minor changes to Fedora’s dist-git branching could transform Fedora from a self-contained software distribution into the central hub in a federated, language-agnostic package registry, providing an essential tool that addresses the needs of an underserved developer community.
]]>